-
RepSum: Unsupervised Dialogue Summarization based on Replacement Strategy(ACL 2021)카테고리 없음 2022. 6. 20. 18:03
paper link : https://aclanthology.org/2021.acl-long.471/
Dialogue summarization이란?
Court debate, CS call from customer 등 두 명 이상의 화자의 담화를 바탕으로 여러 turn으로 구성된 대화에서 핵심 정보만을 추출하여 간결한 표현으로 함축한 것이다. Dialogue를 구성하는 utterance가 짧다는 특성, 화자가 여러명이라는 특성은 모델이 dialogue summarization하는데 어려움을 겪는 원인 중 하나이다.
Previous works
기존의 dialogue summarization을 다룬 연구들은 충분한 supervised label들이 있는 상태에서 진행되었다. 그러나 label이 충분하지 않은 상태에서는 해당 연구들을 그대로 사용하는데에 무리가 있었다. 그 결과 unsupervised 방식의 dialogue summarization이 연구되었고 두 가지 방향으로 요약될 수 있다. 1. Utterance를 directly extracting, 2. edit-distance-based 방식이다.RepSum Model
본 논문은 기존의 연구와는 다른 방식으로 unsupervised dialogue summarization 테스크를 다룬다.
"superior한 summary는 original dialogue의 replacement가 될 수 있다" 라는 주장을 바탕으로, auxilariary task를 진행 할 때 original한 dialogue 대신 summary를 사용해도 동일한 정보값이 나와야 한다 라고 주장한다. 해당 주장을 바탕으로 이전에 나온 unsupervised dialogue 모델들 보다 우수한 성능을 보인다.

img1) auxilary task Auxilary task로서, n 번째 utterance를 generate하거나, classify하는 task를 만든다.
9개의 utterance로 이루어진 dialogue가 주어졌을 때, 1~8번째 utterance, 9번째 utterance로 dialogue를 쪼갠다. 그리고 auxilary task를 진행한다.
Img1에서 좌상단 dialogue,우상단 summary에서 utterance를 generate하고 실제 dialogue에 있었던 9번째 utterance와 difference를 쟨다. 그리고 (좌상단에서 generated, 우상단에서 generated)간의 difference도 최소화 하여 동일한 정보를 generate 하도록 한다. 이를 그림으로 표현하면 img2와 같다.

img2) img1의 generalized version TG (Auxilary task - generation)
n번째 utteancefmf generation하는 task이다. 앞서 남겨둔 9번째 utterance와 얼마나 유사하게 utteance를 generate 했는지 측정하는 branch이다. img2의 좌하단 부분이다.
bi-directional LSTM으로 구성된 encoder와, uni-directional LSTM directional LSTM으로 이루어진 decoder로 구성되어있다.
for the sake of fair comparison with other baseline을 위해 해당 모델들을 사용했다고 한다.
Dialogue 내에 모든 utterance를 모두 concat하여 encoder에 집어넣는다. Attention기반 네트워크를 바탕으로 9번째 utterence로 decoding한다.

equation 1 Output word의 probability distribution은 equation 1과 같다. y를 제외한 모든 값은 learnable한 파라미터들이고, tanh로 activation한다.
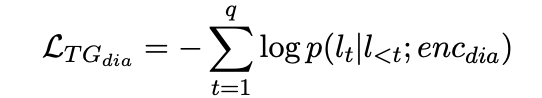
eqation 2 1. Equation 2와 같이, 다음 등장할 uttrance와 GT간의 difference를 NLL loss를 최소화 한다. (식에는 dialogue 만 나와있지만 summary 도 똑같은 방식으로 진행)
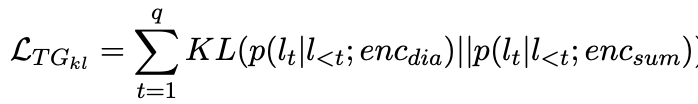
equation 3 2. Dialogue에서 generated 한 utterance와 summary에서 generate한 utterance가 비슷하도록 KLdiv. (equation 3)

Generation에 대한 Total loss는 equation 4와 같다.
TC (Auxilary task - classification)
img2의 좌하단, 몇 가지 utterance가 주어졌 때 맞은 utterance를 classify하는 branch이다. 인코더는 역시 bi directional LSTM을 사용한다.
img1에서 9번째 utterance를 GT로 놓고, 나머지 classification의 후보로 들어갈 data는 다른 dialogue에서 random sampling 해온다. 해당 utterance를 LSTM 에 태운 값을 represenation 1이라고 하겠다. (즉 representation은 candidate utterance마다 다름)
Dialogue/summary를 LSTM 에 태운값을 representation 2라고 명명하고, [rep1, rep2]로 concat 한다. (모든 candidate representation 1과 concat 되는 representation 2는 같음)
Classifier를 통과했을 때 GT의 label이 classifier을 통과한 결과가 1, 나머지는 0이 되도록 학습을 진행한다.
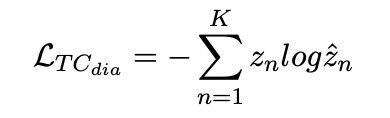
equation 4 올바르게 예측했는지를 알아보는 loss인 equation 4이다.
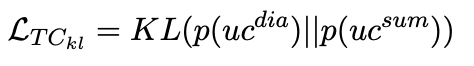
equation 5 dialogue, summary에서 나온 값이 비슷하게 해주는 KIDiv인 equation 5 이다.

equation 6 Total classification loss인 equation 6이다.
Unsupervised summarization : Extractive
좋은 summary를 generation하고자 하는 방법 1 이다. 여태까지는 auxilary task에 대한 설명이었다.
Dialogue를 sentence레벨로 임베딩 하고 binary classify하여 1인 문장만 extraction하여 summarization하는 방법이다.
(Nallapati el al, 2017 을 사용함)
해당 방법으로 summary로 optimize했을 때 loss가 최소가 되도록 equation 7로 학습한다.

equation 7 Unsupervised summarization : Abstractive
인코더-디코더 구조를 사용한다.
label이 있는 상황이었다면 첫 번쨰 토큰을 생성할 때, 우리가 가진 vocab에서 등장할 확률이 가장 높은 단어를 선택하고 softmax-> argmax를 하면 좋았겠지만 현재 task는 label이 없다.
그리고 본 논문은 auxilary task로부터 loss를 계산하여 backprop을 타고 올라가야하는데, argmax는 미분 불가능이다. 따라서 다음 식을 사용한다.
ST(straight - Trough) Gumble Estimator

equation 8, ST Gumble Estimator 해당 식을 사용하면 "미분 가능한 argmax" 를 사용하는 효과를 얻을 수 있다고 한다.
여기에 더해 abstractive summarization 방식에서 추가적인 loss를 사용한다.
Fake summary loss, language modeling loss 이다.
Fake summary loss : 디코더가 어떠한 label에 대한 가이드 없이 summary를 생성해야 하는데, 해당 loss없이 학습하면 학습이 잘 되질 않는다. Extracted된 summary를 fake summary로 사용하고 각 단어를 teacher forcing 해주면 수렴이 잘 이루어졌다고 한다.
Language modeling loss : 레이블이 없이 생성된 summary는 readability/fluency가 부족하므로, dialogue utterance를 사용하여 이 문제를 해결한다.

equation 9 Language model을 pretrain 하고, LM에서 t번쨰 단어가 등장할 확률과 summarization 모델에서 t번쨰 단어가 등장할 확률이 비슷해지도록 loss를 준다.

equation 10 Abstractive summarization에 대한 total loss는 equation 9와 같다.
Experiment
Dataset으로는 Ami dataset/Justice dataset을 활용했다.
영어, 중국어로 이루어진 데이터셋을 활용 했고, 판사의 요약등이 label로 있는 dataset이라고 한다.

img3 평가 지표 두 가지는 다음과 같다. Oracle, LEAD
Oracle : utterance를 그리디하게 추출해서 ROUGE score를 최대화 한다. 모델로서 달성할 수 있는 최대 upper bound를 찾는다.
LEAD : Dialogue에서 첫 n개의 문장을 순서대로 추출하여 요약문으로 활용한다.
본 논문이 두 평가 지표에서 가장 좋은 수치를 나타낸다.

img4 사람이 평가했을 때에도 본논문이 우수하다. 슬프게도 100명의 대학원생이 실험당했다고 한다.
k는 평가에 대한 reliablilty를 나타낸다.